Introduction
In recent years, artificial intelligence (AI) has increasingly present in governance contexts. In Australia, for example, about 30% of Australian employers use AI recruitment tools (Taylor, 2025). But reality is far more complex. Even if a system judges the job seeker based on job fit, it may treat mainstream samples as the norm and identify marginal experiences with biases. For example, in AI interviews, the average transcription error rate for native English speakers in the US is less than 10%, but this rises to 12% to 22% for non-native speakers with foreign accents (Taylor, 2025). In other words, AI is not re-judging without considering all factors, but automating, scaling up, and hiding problematic judgments behind seemingly reliable evidence , building upon existing data distribution, database biases, and commercialization (Noble, 2018, p.30). The impact of automation extends far beyond accents and jobs. As Noble (2018) points out in the chapter “A Society, Searching” ,algorithmic outputs can reorganize racial and gender inequalities into seemingly natural and reliable information rankings. Given the growing use of AI, what risks should we pay attention to?
What is AI?
Artificial intelligence (AI) can be defined as “an AI system is a machine-based system“An AI system is a machine-based system that, for explicit or implicit objectives, infers, from the input it receives, how to generate outputs such as predictions, content, recommendations, or decisions that can influence physical or virtual environments. Different AI systems vary in their levels of autonomy and adaptiveness after deployment”(AI Principles Overview – OECD.AI, n.d.) .

Figure 1. Illustration of the original position
Note. From “Original position,” by Wikipedia contributors, April 12, 2026, Wikipedia .
Veil of Ignorance (Ethics Unwrapped, 2023): It prevents everyone from knowing their race, social status, gender, and their own or others’ views on how to live a good life (Wikipedia contributors, 2026). AI governance can be understood as performing governance actions while shielding all these factors.
Given this background, this blog argues that the risks of AI governance result from the intrinsic characteristics of AI itself:
- It relies on data training.
- It makes judgments through statistical induction.
- It is built into large-scale platform systems.
- It is deployed within existing power structures.
Therefore, once AI is used for governance, it will face challenges such as the spread of biases, the compression of limited experience, and its shaping by capital, with the difficulty in defining responsibility.
Governance deficiencies caused by technological characteristics
Data Is Not Neutral: Manipulation as a Governance Challenge
In the discussions of algorithmic systems and artificial intelligence, data is treated as if it were neutral raw material that can be feed into a system, and the system will produce the accurate, objective, and trustworthy outcomes automatically. However, this assumption is somehow misleading as AI governance depends on training data, user feedback, and systems that automatically sort and rank information. According to Just and Latzer (2016), algorithmic selection works by assigning “relevance” to pieces of information through automated statistical assessment (p.242). In other words. Instead of neutrally identifying what is true, AI systems organise and prioritise information based on their inputs. Therefore, once the input can be manipulated, the output can no longer be treated as reliable. In a similar tone, as Janssen et al. (2020) argue, AI and algorithmic systems rely on data combined from multiple sources, and without proper control over data quality and compliance, such systems are too risky for consequential decision-making (p.1). They further note that interoperability can allow inaccurate data to spread across systems, while mistakes and bias embedded in historical training data may be reflected in algorithmic outcomes (p.5).
Figure 2. Tay.ai Twitter profile screenshot
Note. Screenshot of Microsoft’s Tay chatbot’s Twitter profile. From “Microsoft’s Tay is an AI chat bot with ‘zero chill,’” by N. Summers, July 19, 2019, Engadget . Copyright 2019 by Engadget.
We can already observe obvious malicious contamination, such as deliberate injection of hateful, false, or biased content into systems. Tay, the chatbot which Microsoft launched on Twitter in 2016. Tay was designed to learn user interactions, but it quickly started reproducing racist and sexist content, forcing Microsoft to take it offline within 24 hours of its launch (Baron, 2016). Microsoft later said that some users had purposely used Tay to get it to give wrong answers (Worland, 2016). In this case the automated system was vulnerable because it used interaction data from a data environment that was biased and had problems.
This means that data is not a naturally neutral “material” that can be directly input into algorithms or AI systems. I urge that criticism of AI or algorithmic systems should not stop at whether the data is transparent but should also question where the data comes from, how it is filtered, who defines it, and whose interests it serves. We can only understand how AI, algorithmic systems, automation, and information manipulation are related if we see data as a social and cultural basis for governance.
Bias in Dataset itself as a Governance Challenge
The second governance challenge posed by artificial intelligence lies in dataset bias. Even without explicit malicious contamination, AI systems still produce distorted or biased results because the datasets they use cannot be collected and retrieved objectively and impartially. As these systems learn from existing data, they repeatedly learn from mainstream data, thus ignoring marginalized groups.
Unlike data pollution, dataset bias does not involve the deliberate insertion of false or hateful content into the system. Instead, the issue lies in the structure of the dataset itself. As AI systems are trained to identify patterns, they cannot simply reflect reality, but rather learn from a given distribution. This means that most data reflect the dominant groups (Bender et al., 2021, p.613) and dominant language patterns (Sheard, 2025, p.270) in the training data, which are treated as the default standards in AI training.
This indicates a broader issue in governance. Even if the system treats every piece of data equally during AI training, differences in the datasets themselves can still lead to unequal results. For instance, the experiences of marginalized minority groups and non-mainstream topics, appear less frequently in the training data, Mainstream views of minority groups usually appear more often in the data. After extensive training, AI systems will treat more common viewpoints as the standard, while minority groups are more likely to be misclassified, ignored, or treated as exceptions. In this way, the result may seem objective, but in reality, it perpetuates the various inequalities that already exist in society.
Noble’s (2018) study on search engines exemplifies this phenomenon. Noble points out that search results amplify racist and sexist stereotypes through seemingly neutral ranking systems. Her research shows that the output of the algorithm is influenced by the technical design and the historical inequalities inherent in the existing data (Noble, 2018, p. 30). In this sense, AI governance is not just about processing data, it also turns patterns in data into judgments about importance, normality, and priority.
Therefore, the bias in the dataset or system itself shows that the risks of AI governance do not arise only from malicious manipulation, but also from the uneven structure of the data itself. When a data pattern appears repeatedly until it is regarded as the standard in training data, artificial intelligence systems, under the guise of technological neutrality, will replicate or even reinforce existing social inequalities.
Power Asymmetries in AI Governance
The third problem with AI governance is that it relies too much on resources that are only available to a few people. Artificial intelligence is a capital-intensive product requiring massive amounts of computing power, infrastructure, labor, and data (Bender et al., 2021, p.619). This resource intensity is visible in recent empirical estimates of model training costs.
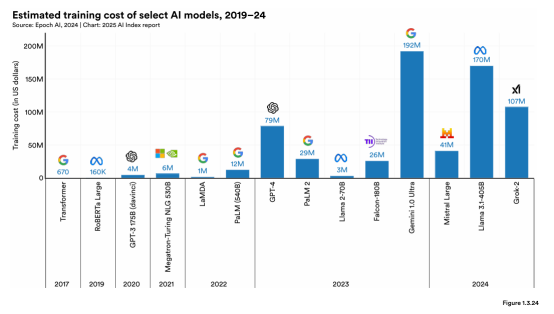
Figure 3. Estimated training cost of select AI models, 2019–24
Note. From Artificial Intelligence Index Report 2025 (Figure 1.3.24), by N. Maslejet al., AI Index Steering Committee, Institute for Human-Centered AI, Stanford University. CC BY-ND 4.0.
As shown in Figure 3, development investment grew rapidly between 17 and 24 years, and only institutions with a solid economic foundation and infrastructure were able to participate in and contribute to the field of artificial intelligence.
Crawford (2021) points out that artificial intelligence is “both tangible and material, composed of natural resources, fuel, human resources, infrastructure, logistics, history, and classification” (Crawford, 2021, p.8), and that “because building AI on a large scale requires substantial capital” (ibid), such systems are “ultimately designed to serve existing dominant interests” (ibid). The construction of AI relies on large-scale resource extraction, infrastructure investment, and the acquisition of a skilled workforce. This means that the development of AI is structurally dependent on institutions that already possess wealth, technological capabilities, and political influence.
Bender et al. (2021) pointed out a similar view from the perspective of large-scale language models. The funding requirements for building such systems “set a barrier to entry” (Bender et al., 2021, p.619), as a result, only a limited number of actors can participate in this field, and access to advanced AI technologies is unevenly distributed. The effects of this barrier to entry are visible in the institutional distribution of frontier AI development.
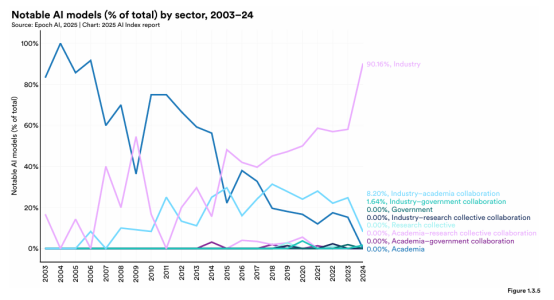
Figure 4. Notable AI models (% of total) by sector, 2003–24
Note. From Artificial Intelligence Index Report 2025 (Figure 1.3.24), by N. Maslejet al., AI Index Steering Committee, Institute for Human-Centered AI, Stanford University. CC BY-ND 4.0.
As shown in Figure 4, the significant development of artificial intelligence models in 2024 was primarily driven by industry. This indicates that the forefront of artificial intelligence research is increasingly controlled by participants with substantial funding, computing power, and infrastructure. They also noted that “the resources required to train and tune state-of-the-art models can exacerbate economic inequalities” (Bender et al., 2021, p.618), suggesting that the development of AI not only reflects existing inequalities but also intensifies them (Bender et al., 2021, p.613). When only a small number of actors can afford to develop and expand the scale of AI systems, the gains in productivity are concentrated among large technology firms, platform companies, and state supported institutions. This centralization has direct consequences for governance. When AI is costly to build,decisions are more often shaped only by the institutions that have the resources to fund and operate these systems. This means that the development of AI is less likely to reflect broader public needs and more likely to serve the interests of those actors with power.
From this perspective, the very act of building artificial intelligence is a reflection of social power, which gives a small number of actors disproportionate influence over the design and use of automated governance, just as Crawford (2021) states, “artificial intelligence is a registry of power” (p.8).
Conclusion
To sum up, from this blog, it is clear that the core risk of Al governance is reflected by the extension of existing power structures. From manipulated and biased data to capital-intensive infrastructure and centralized institutional power, Al systems embody reproduce the values and hierarchies of their built environment. In this sense, automated governance is far more than just a technological issue. The foundations upon which Al systems are built include data training, statistics, infrastructure, and power distribution. Al systems are shaped by their training data, statistical methods, underlying infrastructure, and the way power is distributed around them. Finally, these systems are organized, prioritized, and fed back into social reality through governance. However, I want to end with this blog on a more hopeful note: recognizing the risks of Al governance should not lead to pessimism, but to a collective commitment to building systems that are more just, transparent, and accountable.
References
AI Principles Overview – OECD.AI. (n.d.). https://oecd.ai/en/ai-principles
Baron, E. (2016, March 25). The rise and fall of Microsoft’s ‘Hitler-loving sex robot.’ Siliconbeat. http://www.siliconbeat.com/2016/03/25/the-rise-and-fall-of-microsofts-hitler-loving-sex-robot/
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the Dangers of Stochastic Parrots. ACM, 610–623. https://doi.org/10.1145/3442188.3445922
Crawford, K. (2021). The Atlas of AI: Power, Politics, and the Planetary Costs of Artificial Intelligence. Yale University Press.
Ethics Unwrapped. (2023, February 17). Veil of ignorance – ethics unwrapped. https://ethicsunwrapped.utexas.edu/glossary/veil-of-ignorance
Janssen, M., Brous, P., Estevez, E., Barbosa, L. S., & Janowski, T. (2020). Data governance: Organizing data for trustworthy Artificial Intelligence. Government Information Quarterly, 37(3), 101493. https://doi.org/10.1016/j.giq.2020.101493
Just, N., & Latzer, M. (2016). Governance by algorithms: reality construction by algorithmic selection on the Internet. Media Culture & Society, 39(2), 238–258. https://doi.org/10.1177/0163443716643157
Maslej, N., Fattorini, L., Perrault, R., Gil, Y., Parli, V., Kariuki, N., Capstick, E., Reuel, A., Brynjolfsson, E., Etchemendy, J., Ligett, K., Lyons, T., Manyika, J., Niebles, J. C., Shoham, Y., Wald, R., Walsh, T., Hamrah, A., Santarlasci, L., . . . Oak, S. (2025). Artificial Intelligence Index Report 2025. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2504.07139
Noble, S. U. (2018). Algorithms of oppression: How Search Engines Reinforce Racism.
Sheard, N. (2025). Algorithm‐facilitated discrimination: a socio‐legal study of the use by employers of artificial intelligence hiring systems. Journal of Law and Society, 52(2), 269–291. https://doi.org/10.1111/jols.12535
Summers, N. (2019, July 19). Microsoft’s Tay is an AI chat bot with “zero chill.” Engadget. https://www.engadget.com/2016-03-23-microsofts-tay-ai-chat-bot.html
Taylor, J. (2025, May 14). People interviewed by AI for jobs face discrimination risks, Australian study warns. The Guardian. https://www.theguardian.com/australia-news/2025/may/14/people-interviewed-by-ai-for-jobs-face-discrimination-risks-australian-study-warns
Worland, J. (2026, February 22). Microsoft takes Chatbot offline after it starts tweeting racist messages. TIME. https://time.com/4270684/microsoft-tay-chatbot-racism/
Be the first to comment