Consent is supposed to safeguard digital privacy. The reality is that the majority of the population are unaware of what they are consenting to, and cannot meaningfully regulate the use of their personal data. This blog argues that the modern consent-based model of privacy has failed, leaving individuals exposed in an increasingly data-driven world.
The illusion of Choice

Millions of users are requested to give the same answer every day to either accept or refuse a privacy policy. Users are habitually shown lengthy and convoluted terms and conditions and require clicking on the words I agree to download an app, to subscribe to a service, or to visit a website (Obar and Oeldorf-Hirsch, 2018). Theoretically, this process will provide people with the ability to control their personal data. Practically it hardly does.
This is the problem here. The majority of privacy policies are also composed in thick, technical language that is not easily comprehensible, not to mention well-informed users (Fabian eu al., 2017). They tend to be long, subject to revision, and such as to be cut up so as to make reading them a matter of care. Consent therefore is not as much of an informed choice but more of a necessity. When users are required to use digital services which have become entrenched in daily life, they do not have much choice other than to consent.
The key question here is can privacy really be ensured when consent is not substantial? Recent research indicates that the answer is in the negative. Research indicates that in many instances, people cannot predict how their data will be gathered, shared, or used later, especially in the complicated digital ecosystem (Gupta et al., 2023). This brings a divide between the legal presumption of informed consent and the reality of user experience.
I Agree: But Do we Really?

It is not the mere fact that individuals do not read privacy policies. That the system itself is constructed in such a fashion that it renders real understanding impractical. Users are even trying to make thoughtful choices, but they are working in environments that have been formed by the collection of data, algorithm processing, and opaque information channels. Consequently, this puts the burden of privacy protection on individuals who do not have time and means to engage in meaningful control.
When consent is intended to safeguard privacy, it makes an assumption, which is that individuals know what they are consenting to. However, in the online space, this is not the case.
Studies have continuously indicated that users cannot make informed choices regarding their privacy. A big problem is what scholars refer to as privacy literacy the capacity to comprehend the process of collecting, processing and sharing of personal information. Although most users think that they can handle their privacy, research shows that there is a discrepancy between perceived and real knowledge (Ma and Chen, 2023). Simply put, individuals tend to be confident about their decision even when they are not completely aware of the dangers that they are taking.
This false sense of security is a hazardous circumstance. Users will be more willing to give out personal information without doubts about its usage when they perceive themselves as in control. However, digital platforms function based on sophisticated systems of data tracking, aggregation, and algorithmic profiling that is not easily discerned by the common user. Consent is consequently detached to actual knowledge.
More pronounced is what is referred to as the privacy paradox by the researchers. The fear of privacy is often raised by people, but they share personal information online in large amounts (Kim and Kim, 2020). It is not merely a contradiction or negligence. Instead, it is a manifestation of the digital economic circumstances. The design of social media, communication tools, and online services is created in such a manner that participation requires the sharing of data. Denying permission usually implies being locked out of crucial online areas.
In order to understand how this can be implemented, we can look at how big platforms are offering privacy options. Policies can be packaged together and users are presented with a choice: accept everything or lose access. Setting often get buried in elaborate interfaces, even where they exist. Research, including the Norwegian Consumer Council report about the use of interface design to manipulate users toward providing more data, not less, in digital platforms demonstrates that companies employ interface design to encourage users to provide increasingly more, not less data (Nordal and Myrstad, 2018). These practices are not a coincidence they are designed into the architecture of digital services.
Meanwhile, users are also making choices concerning their own data. In social sites, networks, behavioural patterns, and interactions with other social site users are often used to make a personal inference. It is in the sense that the issue of privacy is no longer personal. Even cautious users may be infected by the behaviour of being exposed to others. Similar to the findings of Hinds, Williams and Joinson (2020), who have studied the responses to the Cambridge Analytica scandal, a significant number of people kept using Facebook even after they realised it was a privacy threat and tended to think that they were not the direct targets of the threat.
This is a more serious problem. The issue does not lie in the fact that people are not taking care of their privacy, but in the fact that the system imposes impractical expectations on people to do that. Consent presupposes that users are capable of assessing risks, comprehending the further ways to use data, and make rational choices in complex situations. These expectations are seldom realized in reality. Whether users are more careful or not, is no longer a question. The question is whether any system that is so much dependent on individual consent can ever be of any significance in terms of privacy provisions.
When the Bubble Pops: Consent Failure
To see why consent does not work in practice, it is useful to consider an example of consent in the real world. One of the brightest examples of how personal information may be misused is the Cambridge Analytica scandal, where users did not anticipate, and could not agree to, how their personal information would be used.

In 2018, the political consulting firm Cambridge Analytica was found to have accessed information of millions of Facebook users without their direct consent (BBC News, 2018). Originally, the data was gathered via a personality quiz application but more importantly, data was also mined on Facebook networks of the users. This enabled the firm to create a huge data set much higher than those who had physically engaged with the application. The manner in which this was done can be well explained by the BBC report on the scandal here
The focus of the controversy was not on how the data was collected but on the usage of the data. Cambridge Analytica created psychographic profiles, detailed models of the prediction of personality traits and behavioural tendencies. The profiles were subsequently applied to send political advertisements specifically targeted in the 2016 United States election (Brown, 2020). Personal information was in effect turned into a weapon to affect political decision making.
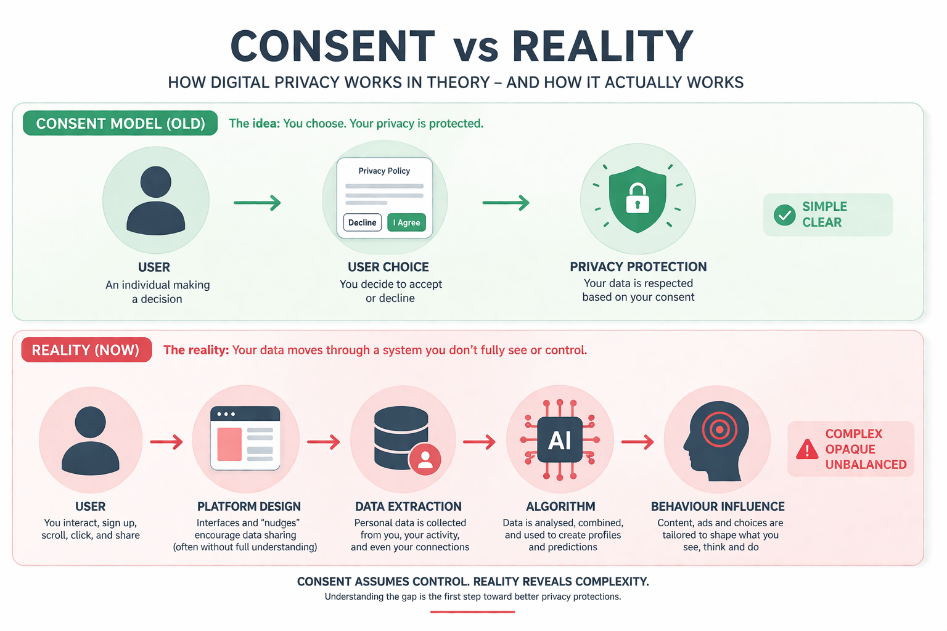
Legally, Facebook users had agreed technically to having their data collected using the platform by the terms of service. This consent was however not applicable to how their data was finally reused. The scandal, as Hu (2020) explains, revealed the black box character of algorithmic systems, where the users are not in a position to view or comprehend the way their data is handled or utilized. This obscurity is counterproductive to informed consent.
The regulatory reactions also point out the limitations of the existing system. In 2019, the Federal Trade Commission of the U.S. fined Facebook a record-breaking 5 billion dollars over privacy breaches. Although this was among the biggest fines of its kind, critics claimed that it had minimal impact on transforming the data practices. The official FTC announcement describes the details of the enforcement action.
The most telling is, perhaps, the response of users. Although most people were outraged by the events and some even participated in campaigns like #DeleteFacebook, a significant number of people still used it with some slight behavioural changes (Hinds et al., 2020). That is part of a bigger trend where users are entrenched within systems with hard-to-leave privacy hazards in which privacy hazards become apparent.
The Cambridge Analytica case tells a fundamental flaw in the consent model. Users can consent to provide information in one situation, and the information can be utilized in completely new manners. Privacy, according to Nissenbaum (2015), is not so much about the sharing of information, but rather about its use in the proper context of its origin. Perceived as such, the matter is not just a misuse of data, but the inability of digital systems to consider contextual limits. Consent is narrowly on a point of agreement but does not consider data flows, development and use in the long term. This renders it an insufficient basis on privacy protection in the digital contemporary world.
Why Privacy, Power, and Limits to Consent Matter
The consenting failure is not merely a technical issue. It is a question of power.
In the modern digital world, personal information is no longer gathered, but analysed, bought and sold to influence behaviour. With the emergence of data as the core of economic and political systems, the ability to control information is turned into power to control people (Kaya and Güllüpinar, 2025). That is why the issue of privacy could not be a personal matter anymore, but the matter of rights and governance. With the changing nature of the discussion surrounding digital privacy, academics and policymakers have started to conceptualize it as a subset of a broader range of digital rights, as the issues of surveillance, data profiteering, and information system inequality have become increasingly important (Goggin et al., 2019).
Meanwhile, the lines between state and corporate surveillance have become unclear. Both the government and non-government actors now contribute greatly to the surveillance and analysis of personal information as debates after the Snowden revelations suggested. The Guardian analysis provides a helpful summary of the ways in which mass surveillance transformed privacy issues around the world:
This change is important since it breaks the belief that people can safeguard themselves using their own decisions. As data transfers between platforms, institutions, and jurisdictions, individual consent is simply not a realistic consideration of the scope or complexity of data utilization.
Further, even the law has been finding it difficult to catch up. Privacy frameworks are still largely based on the concept of consent, although increasing evidence suggests that it is not working in practice. As Gupta et al. (2023) show, people would be more willing to disclose data when there are other guarantees, including transparency, surveillance, and data erase options. This implies that privacy protection should be taken beyond consent to more structural protection.
This shift is starting to be reflected in a growing number of regulatory efforts. As an illustration, the European Union General Data Protection Regulation (GDPR) puts greater requirements on organisations, such as data minimisation and accountability requirements. The overview of GDPR by the European Commission, clearly explains these principles. These reforms are not without limitations though. There is still unequal enforcement, and international digital platforms still continue to act between jurisdictions and usually take advantage of the discrepancies between legal frameworks.
But what in practice does this mean?
It implies that privacy cannot be only based on whether people can agree to it by clicking on the I agree button. A serious strategy on digital privacy needs to appreciate that people are working within systems that they have no control over. Privacy protection thus involves putting the onus on the organisations that gather and utilize data rather than on the users.
Where it Leaves us?
Consent has always been the cornerstone of the privacy law since it is supposed to provide individuals with freedom and choice over their personal data. However, in the digital age that promise is growing hollow. Users do not usually have time, knowledge, and power to make effective decisions about their privacy behaviour as the Cambridge Analytica scandal and broader studies of the subject demonstrate. Consent is not to be completely lost, but it can no longer be the primary protection measure in digital privacy. The actual protection should be with greater intensity; transparency, accountability, and explicit boundaries on the use of the personal data by the organisations.
References
BBC News (2018), Facebook–Cambridge Analytica data scandal, available at: https://www.bbc.com/news/topics/c81zyn0888lt (accessed 9 April 2026).
Brown, A.J., 2020. “Should I stay or should I leave?”: Exploring (dis) continued Facebook use after the Cambridge Analytica scandal. Social media+ society, 6(1), p.2056305120913884.
European Commission (n.d.), Data protection in the EU, available at: https://commission.europa.eu/law/law-topic/data-protection/rules-business-and-organisations/principles-gdpr_en (accessed 9 April 2026).
Fabian, B., Ermakova, T. and Lentz, T., 2017, August. Large-scale readability analysis of privacy policies. In Proceedings of the international conference on web intelligence (pp. 18-25).
Federal Trade Commission (2019), Facebook agrees to pay $5 billion penalty, available at: https://www.ftc.gov/news-events/news/press-releases/2019/07/ftc-imposes-5-billion-penalty-sweeping-new-privacy-restrictions-facebook (accessed 9 April 2026).
Goggin, G., Vromen, A., Weatherall, K., Martin, F. and Sunman, L., 2019. Data and digital rights: Recent Australian developments. Internet policy review, 8(1).
Gupta, R., Iyengar, R., Sharma, M., Cannuscio, C.C., Merchant, R.M., Asch, D.A., Mitra, N. and Grande, D., 2023. Consumer views on privacy protections and sharing of personal digital health information. JAMA network open, 6(3), p.e231305.
Hinds, J., Williams, E.J. and Joinson, A.N., 2020. “It wouldn’t happen to me”: Privacy concerns and perspectives following the Cambridge Analytica scandal. International Journal of Human-Computer Studies, 143, p.102498.
Hu, M. (2020), Cambridge Analytica’s black box, Big Data & Society,7(2) pp. 1–6.
Kaya, F.K. and Güllüpinar, F., 2025. The Evolution of Attention Economy in the Age of Digital Capitalism: Surveillance of Digital Data and Manipulation of Consumer Behaviour. Journal of Consumer & Consumption Research/Tüketici ve Tüketim Araştırmaları Dergisi, 17(1).
Kim, B. and Kim, D., 2020. Understanding the key antecedents of users’ disclosing behaviors on social networking sites: the privacy paradox. Sustainability, 12(12), p.5163.
Ma, S. and Chen, C., 2023. Are digital natives overconfident in their privacy literacy? Discrepancy between self-assessed and actual privacy literacy, and their impacts on privacy protection behavior. Frontiers in Psychology, 14, p.1224168.
McCurry, J. (2023) ‘Mass surveillance 10 years after Snowden revelations’, The Guardian, 26 June. Available at: https://www.theguardian.com/technology/2023/jun/26/mass-surveillance-10-years-after-snowden-revelations (Accessed: 9 April 2026).
Nissenbaum, H., 2018. Respecting context to protect privacy: Why meaning matters. Science and engineering ethics, 24(3), pp.831-852.
Nordal, V.B. and Myrstad, M. (2018) ‘Deceived by Design: How tech companies use dark patterns to discourage us from exercising our rights to privacy’. Oslo: Norwegian Consumer Council (Forbrukerrådet). Available at: https://www.forbrukerradet.no/side/deceived-by-design/ (Accessed: 9 April 2026).
Obar, J.A. and Oeldorf-Hirsch, A., 2018. The clickwrap: A political economic mechanism for manufacturing consent on social media. Social Media+ Society, 4(3), p.2056305118784770.
Be the first to comment