
What happened on X?
In late 2024, something strange started happening on X (formerly Twitter). Artists weren’t arguing, trending, or going viral—they were quietly leaving. The reason? A small update to the platform’s Terms of Service meant that any artwork posted could now be used to train its AI model, Grok. Almost overnight, illustrators began deleting their portfolios, locking their accounts, or even “poisoning” their own work with subtle glitches to stop it from being scraped.
What used to feel like a creative community suddenly felt… different. Less like a space for sharing, and more like a system quietly taking from the people who made it valuable in the first place.
This isn’t just about one platform or one policy change. It points to a bigger shift in how the internet works today. As AI tools rely more and more on user data, it’s getting harder to tell where participation ends and exploitation begins. Most of us click “agree” without thinking—but what are we actually giving up?
In this post, I want to unpack what’s really going on. AI platforms sound great—they promise speed, innovation, and convenience. But a lot of the time, that comes from quietly using our data in ways we don’t fully understand or control. Using the X and Grok situation as an example, I’ll explore what this means for creators, why the rules aren’t keeping up, and where this might all be heading.
Beyond the Screen: The Extractive Logic of AI Training
To make sense of this, it helps to look at how these platforms actually run behind the scenes. AI doesn’t just magically “know” things—it learns from data, and a huge amount of that data comes from users like us. Every post, image, or click can be collected and turned into something useful for training algorithms. This is what people mean when they talk about “datafication.”
A good example of this is generative AI models, such as those based on Generative Adversarial Networks (GANs), which are designed to learn patterns from large datasets and produce new, realistic content.(Goodfellow, I. et al., 2021) While this can lead to impressive technological advances, it also raises questions about where that training data comes from—and whether users are really aware of how their content is being used.
The tricky part is that this process is mostly invisible. Posting art might feel like sharing with a community, but it can also mean feeding a system that mainly benefits the platform itself. What’s more, AI systems are often difficult to hold accountable because their operations are complex and opaque, making it hard for users to understand how their data is being used. In many cases, people agree to platform terms without fully realising the extent to which their content may be analysed, reused, or incorporated into AI training (Busuioc, M, 2020). Over time, this creates a gap: companies gain more control and value, while users are left with less say in how their own content is used.
Thus, this creates a situation where platforms can continuously benefit from user contributions, while users themselves have limited awareness or control over how their data is actually being used.
When Sharing Turns into Exploitation
This is exactly why the situation on X makes so many artists angry. In late 2024, the platform quietly updated its Terms of Service to allow user-generated content to be used for training its AI model, Grok. The change was not widely announced, but its impact was immediate—many artists began deleting their work, leaving the platform, or even using tools to disrupt AI training.
When the platform updated its Terms of Service to allow user content to be used for training its AI model, Grok, it blurred the line between sharing and exploitation. What used to feel like a space for creative expression suddenly became something else—more like a resource pool for training AI.
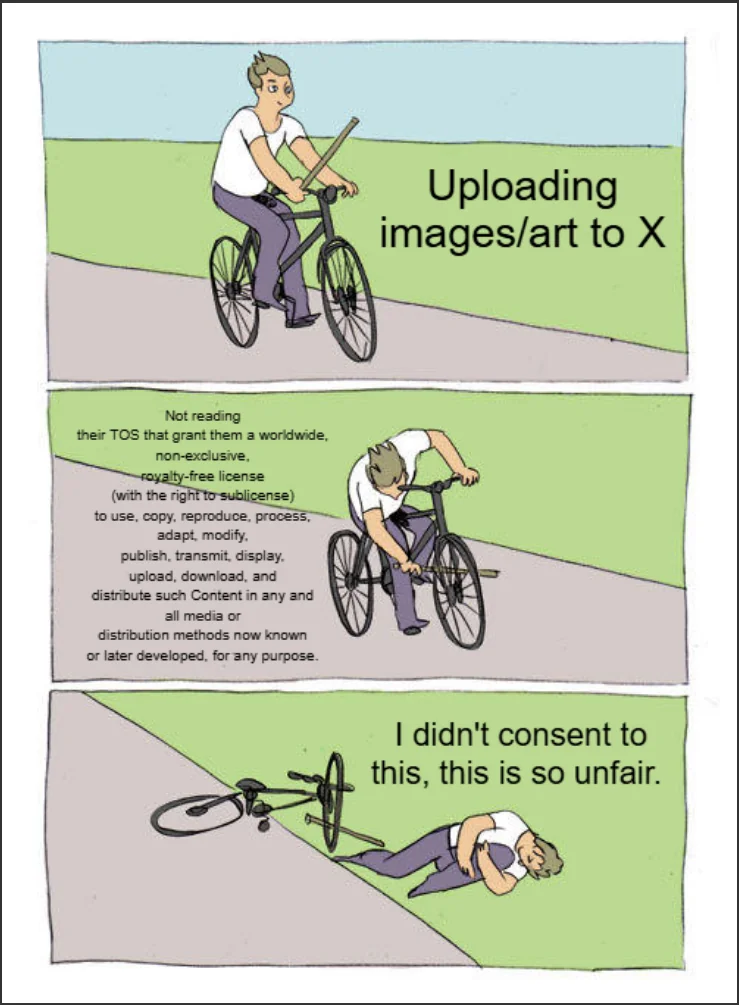
In practice, this data collection is spelled out in the platform’s own rules. According to X’s Terms of Service(X, 2024):
“By submitting, posting or displaying Content on or through the Services, you grant us a worldwide, non-exclusive, royalty-free license (with the right to sublicense) to use…for use with and training of our machine learning and artificial intelligence models.”
https://cdn.cms-twdigitalassets.com/content/dam/legal-twitter/site-assets/terms-of-service-2025-05-08/en/x-terms-of-service-2025-05-08.pdf#page=4.66
This means every image, caption, or interaction can legally be used to train AI—even without users actively realising it. As Kate Crawford (2021) argues in Atlas of AI, artificial intelligence systems are built on the large-scale extraction of data and resources, rather than existing as neutral or purely technical tools. From this perspective, what happens on X is not an isolated case, but part of a broader pattern of turning everyday user activity into valuable data.
For artists, this isn’t just about “data.” Their work often represents hours of effort, personal style, and even their professional identity. Seeing that work potentially used to train AI systems—without clear consent or compensation—raises serious concerns about fairness and ownership. It also explains why some artists chose to delete their work or even “poison” their images to disrupt AI training.
More broadly, this situation highlights a growing power imbalance. Platforms like X are able to set the rules and benefit from large-scale data collection, while individual users have very limited control over how their content is used. Even if these practices are technically allowed through updated policies, they don’t necessarily feel fair or transparent to the people who are most affected.

In response, a lot of artists didn’t just accept the change—they pushed back in different ways. Some deleted their work or left the platform completely, choosing not to let their art be used as training data. Others went a step further and started using “poisoning” tools—for example, Nightshade and Glaze—which subtly alter images to confuse AI models. Imagine you discover someone is stealing your takeout, so you add a huge spoon of super spicy food to it. That’s exactly what artists are doing. They use tools like Nightshade to embed “poison” into the pixels of an image. To the human eye, it’s still a painting, but to AI algorithms (like the GANs we mentioned), it will mistake a cat for a car and the sun for grass. These actions don’t completely stop platforms from collecting data, but they do show how frustrated many creators feel—and how they’re trying to take back at least some control over their work.
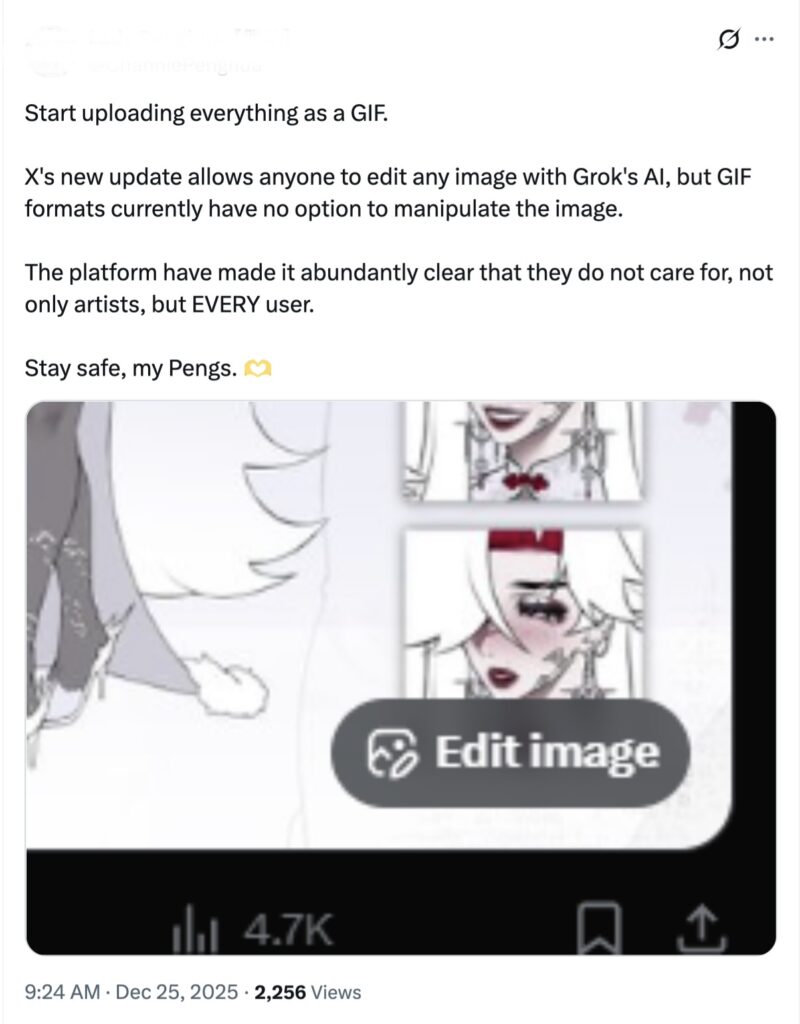

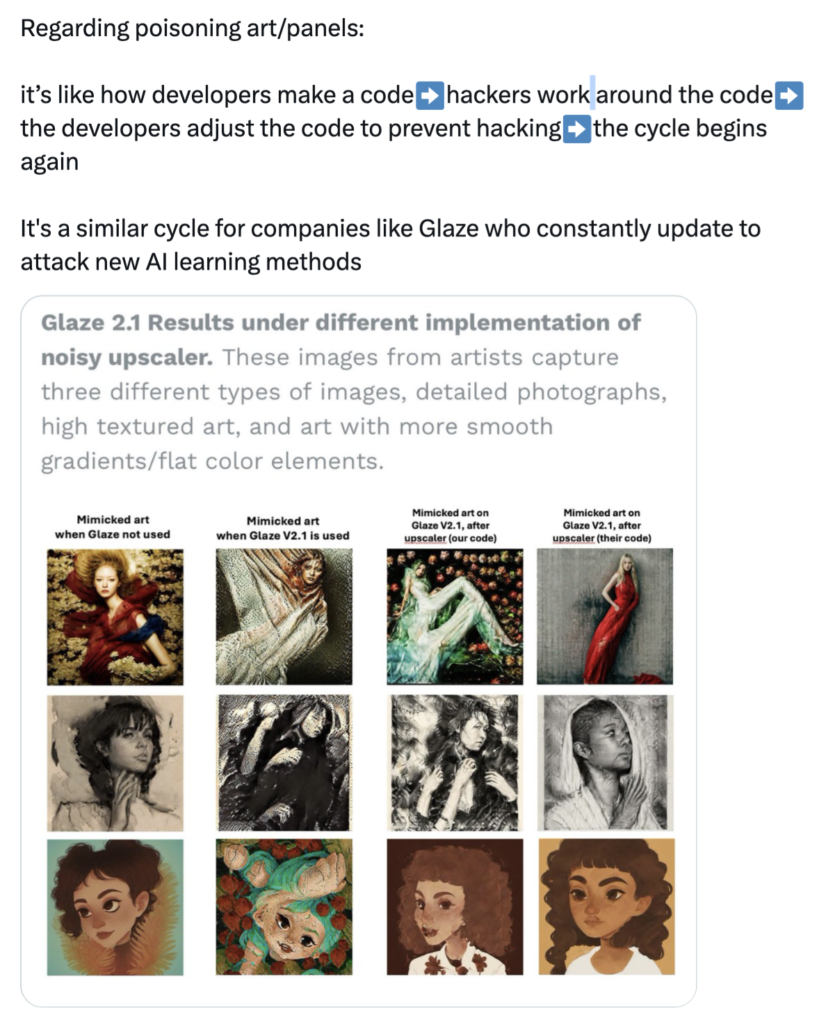
Building on this, research has shown that these concerns are not just hypothetical. A study on AI-generated art points out that many image generation systems are trained on large-scale datasets collected from the internet, often without artists’ consent. This has led to a range of negative impacts, including economic loss, plagiarism, and copyright issues for creators .(Jiang, H. et al., 2023)
In this sense, what is happening on X is part of a much broader pattern. Platforms and AI companies are able to extract value from user-generated content at scale, while the original creators receive little recognition or compensation. This helps explain why many artists see the use of their work for AI training not as innovation, but as a form of exploitation.
The Musk Paradox: Freedom for the Platforms, Mining for the Users
Since we’ve discussed the X platform, we must mention the figure at the center of this storm—Elon Musk. He has consistently marked himself as an “absolute advocate of free speech,” repeatedly claiming his intention to turn X into a global “digital square.” While he’s “freeing” the speech, he’s essentially “trapping” the creators.
This brings us back to what Wirtz et al. (2019) warned about: the “dark sides” of AI when governance is handled in a black box. Musk’s move to turn every user’s art into Grok’s fuel is a classic power play. He’s using his position as a tech billionaire to redefine what “public” means. In his world, if you post it, he owns the right to mine it. It’s not just an update; it’s an ego-driven extraction.
I would like to say this is the ultimate failure of algorithmic accountability. Musk has created a system where he holds all the cards—he owns the platform, he owns the AI, and now he’s claiming he owns the patterns of your creativity. He’s essentially saying, “You’re free to speak, but your soul belongs to my data set.” It’s a hypocritical stance that prioritises his AI ambitions over the actual human beings who made the platform worth visiting in the first place.
If this is his “freedom,” it looks a lot like a digital feudal system where we’re all just serfs tilling the data-fields for his next big project.
The Slippery Slope: Is Your Personal Data Next?
Now, I know what you’re thinking: “I’m not an artist, so why should I care?” But here’s the thing—this isn’t just about a few pretty illustrations. It’s about who really holds the remote control to our digital lives. When a giant platform like X can just decide to feed everything you’ve ever created into an AI, it’s a massive red flag for our “data ownership.”
Think about what Madalina Busuioc (2020) calls “power asymmetry.” It’s basically a fancy way of saying there’s a huge, unfair gap between us and these big tech companies. They have all the tools and the “black-box” algorithms, while we’re often left in the dark about how our data is being chewed up and spat back out. As she points out, when these systems become too opaque, “accountability” just flies out the window. If you can’t see how the machine works, how can you complain when it takes something of yours?
This case with the artists is just the tip of the iceberg—it sets a scary precedent. If they can take a painter’s portfolio today without a “thank you” or a cent in compensation, what’s stopping them from taking your private chats, your selfies, or even the way you express your emotions tomorrow? Not to mention that these things are happening frequently in our lives now. What looks like a niche drama for the art world is actually a huge shift in how platforms extract value from every single thing we do online. We’re moving from being “users” to being “unpaid raw material.”
WANTED: Better Regulation and Governance
Though we’ve talked about the “digital poisoning” and the mass fleeing to other platforms, we can’t just “Nightshade” our way out of this forever. We need some actual Governance. To be honest, relying on tech giants to “do the right thing” is like leaving a cat in charge of the goldfish. It’s just not a solid plan. What we actually need is real, transparent AI Governance.
Araz Taeihagh (2021) suggests we shouldn’t just wait years for slow-moving laws to catch up. He talks about a “soft law” approach. Think of it as a set of collaborative guidelines where platforms, artists, and regulators actually sit at the same table to decide what’s fair. Instead of being “mined” for data, creators should be treated as key stakeholders.
And it’s not just about copyright. Wirtz and his team (2019) have been looking at the “dark sides” of AI, and they’re calling for a “systematic regulation process.” Basically, they’re saying we need a big-picture strategy where governments and tech companies actually work together (instead of X just doing whatever it wants in a black box). We need to move away from this “move fast and break things” attitude and toward a system that actually accounts for human impact.
So as we move further into this AI-driven world, it’s only fair that we have a seat at the table. After all, if our data is powering these systems, we should have some say in where they’re headed.
Reference
Busuioc, M. (2020). Accountable Artificial Intelligence: Holding Algorithms to Account. Public Administration Review, 81, 825 – 836. https://doi.org/10.1111/puar.13293.
Crawford, K. (2021). The Atlas of AI: Power, Politics, and the Planetary Costs of Artificial Intelligence. Yale University Press.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2021). Generative Adversarial Networks. 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), 1-7. https://doi.org/10.1109/icccnt56998.2023.10306417.
Jiang, H., Brown, L., Cheng, J., Khan, M., Gupta, A., Workman, D., Hanna, A., Flowers, J., & Gebru, T. (2023). AI Art and its Impact on Artists. Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society. https://doi.org/10.1145/3600211.3604681.
Taeihagh, A. (2021). Governance of artificial intelligence. Policy and Society, 40, 137 – 157. https://doi.org/10.1080/14494035.2021.1928377.
Wirtz, B., Weyerer, J., & Sturm, B. (2020). The Dark Sides of Artificial Intelligence: An Integrated AI Governance Framework for Public Administration. International Journal of Public Administration, 43, 818 – 829. https://doi.org/10.1080/01900692.2020.1749851.
X. (2024). Terms of Service. X. https://www.x.com/en-us/tos
Be the first to comment