Have you ever felt like your phone is reading your mind? You think about a pair of shoes, and suddenly, they appear in every ad you see. It feels like magic, but it’s actually the work of the “Invisible Script”—the black-box algorithms that govern our digital lives.

source: iStock
In Berlin at the beginning of the 20th century, the crowd gathered in a miracle: a horse named Hans, who could solve complex arithmetic by knocking his hooves. Even the top scientists at that time were equally confused, and finally they found out the truth. Hans is not doing mathematics but studying human beings. At the moment when the correct answer appeared, he keenly captured the almost invisible physical clue of the questioner’s physical relaxation – the horse was born without counting. In essence, he is a perfect statistical imitation machine.(Crawford, 2021).
A century later, we find ourselves surrounded by digital versions of Clever Hans. Modern AI systems, much like the famous horse, operate through what Frank Pasquale describes as a Black Box —systems that produce impressive outputs while hiding the underlying logic of their predictions.

source: Wikipedia
When Prediction Starts to Feel Like Mind Reading
Today, this historical story makes people feel an inexplicable sense of familiarity. When our smartphone accurately predicts the shoes we calculate in our hearts, this experience is like a kind of magic. But as Kate Crawford (2021) pointed out, this seemingly predictable performance is essentially just a high-speed process of detecting clues and matching patterns. We are not understood. We are just patterned by AI through some labels.
These AI platforms don’t actually need to spy on our minds. They only need to harvest enough fragments of user behavior. Every pause on the screen, every geographical anchor point, every impulsive click is a signal. These fragments are carefully assembled into predictive portraits of various users. With each slide, the simulated intelligence becomes more and more real, which even makes you begin to doubt whether the algorithm knows yourself better than you.
Over time, we will live in a digital environment that seems to know you and even seems to be a little intimate, but in essence it is still just a statistical inference. These systems do not understand the context, meaning or intention like humans. They are just good at extracting patterns from massive behavioral signals and then packaging these patterns into convincingly convincing predictions. What is really worth being wary of is that this prediction looks more and more like understanding itself. Once we begin to take the judgment of the AI platform as the rule of our life, we are more likely to ignore the invisible Black Box logic hidden behind it.
Algorithms Do More Than Organise Information
It is easy for people to regard algorithms as a neutral tool, just to help us deal with too much information on the Internet. In this understanding, the algorithm sorts out the Internet content for us and sorts it according to relevance to make our digital life more efficient. But this statement is too narrow. As Just and Latzer (2017) pointed out, algorithm selection has gradually become an important source of social order and reality construction. This means that algorithms not only sort out the information that already appears on the Internet; they also actively choose what will be made visible, credible and important first. The content we come into contact with on the Internet is never just presented as it is in the real world. It has already been filtered by a set of systems, which will select certain information to display more priority.
That’s why the importance of algorithmic ability far exceeds the convenience of users. When the platform begins to decide what is related to it, they actually affect what users trust and are most likely to remember. Search engines will put the answer first, but it’s not just to save users’ time. The recommendation system will not continuously push specific videos and topics to users, not just provide entertainment. These systems quietly sorted out our reading. They guide users on specific routes and keep them away from other routes. This process is usually very smooth and almost disappears from the background. This is also the reason why this problem cannot be simplified to a separate platform. Take TikTok’s recommendation system as an example, which is highly personalized and very effective. This is because it can learn from very subtle behavioral signals and quickly adjust the content that appears in the user’s information flow. The core of the problem is not only that algorithms can be effectively converted according to users’ preferences, but also that they are increasingly involved in the actual process of forming users’ understanding of the social world. When we realize this, the idea that algorithms are just passive tools to sort out information can no longer be established.
The Problem with the Black Box
If algorithms do far more than sorting information, then the question is no longer just whether they give search results efficiently. The deeper problem is that they often operate in the black box way as Frank Pasquale (2015) said. The system can output significant results, but hides its internal logic from the public eye. The results that users can see are not limited to pop-up ads, recommended videos, and top-rankined answers, but they rarely know how the results are generated, which signals are prioritized, and what kind of presets affect the final output. On the surface, it is a smooth and convenient digital experience, but in fact, it is built on a huge information asymmetry.
This asymmetry is important because the platform understands us more and more, but rarely explains how it analyzes us. They collect trajectory on a large scale, convert these trajectory into various labels, and then feedback these judgments to our digital environment. However, the standards behind these decisions are always difficult for users to master. Why is one result more important than others? Why does one user read contributions, products and answers, but another user doesn’t? These are not irrelevant technical details, but issues about visibility, classification and permissions. When algorithms begin to determine what people are exposed to on the Internet, opacity is no longer a simple technical problem, but a social governance problem. This is also the reason why the black box is not just a confidential problem in a narrow sense. It has something to do with that mechanism. The hidden artificial intelligence system quietly shapes people’s cognition under the seemingly neutral surface. As Noble (2018) pointed out when discussing search engines, people often regard problematic search results as only a reflection of social reality, but in fact, the system architecture itself is involved in the classification and justification of certain specific forms of knowledge.
When Search Stops Showing Results and Starts Giving Answers
This change is especially evident in Google’s AI Overviews case. Traditional search engines operate by providing users with a sorted list of search results. Even if this sorting itself is affected by the algorithm priority, users still need to switch and compare pages between different results and piece together the answers by themselves. AI Overviews has changed this relationship. Google no longer only directs users to the source of information, but directly places a summary generated by AI at the top of the page, directly presenting a seemingly ready-made answer.
In 2024, Google’s AI Overviews model was launched to the public on a large scale, and then it also admitted that some of the overview content had some inaccurate or absurd problems, so Google added new restrictions and adjustments. What’s really important is that it’s not just this system that sometimes goes wrong. Search has always had some sorting, filtering and selection processes. But AI Overviews has further pushed this power to the level of interpretation. What the platform can do is not only to help users find relevant results, but also to package these results into a seemingly reasonable narrative before users click. This changes the relationship between users and knowledge. An automatically generated answer at the top of the page will be more reasonable than a string of competing links. It compresses uncertainty and reduces the search cost, as if the platform has finished thinking for users. In terms of this question, what Google has done is not only to sort out information more efficiently, but more like a deeper understanding of what is useful and credible to be involved in shaping.
The controversy surrounding AI Overviews illustrates the importance of this point. Google interprets many early problems as the system misreading user queries, insufficient quality of source materials, or citing ironic and low-quality user-generated content. In order to solve these problems, it then deals with them by limiting the triggering scenarios of AI Overviews and adjusting the handling of certain sources. However, this response further triggered people to think about the core issue. Users still can’t really see how the platform deals with the criteria of relevance, authority and reliability. The black box has not disappeared. It has just been moved to a position that is easier for users to see and believe. Therefore, the key to the problem is not only product design, but that the platform is gaining an increasing power. They are transforming the search from a tool to help users navigate information to a system that prioritizes public knowledge.
Bias Is Not Just a Glitch
People may tend to understand the problem of AI Overviews as a temporary technical error, just a few strange answers, a few bad sources, and a system that only needs to continue to fine-tune. But this explanation is too easy. The problem is not that the algorithm occasionally makes mistakes, but these errors themselves expose the deeper value orientation problem within the system. As Safiya Noble (2018) pointed out, problematic search results cannot be understood as a simple reflection of social reality. Search systems not only reflect existing ideas, but also sort, standardize and give them legitimacy.
Take the now well-known example of “glue pizza”. When users ask how to prevent cheese from slipping off the pizza, Google’s AI Overviews suggests adding glue. Later, Google admitted in the official description that this kind of answer was summarized with ironic forum content, and said that it then adjusted the algorithm to reduce the impact of such content on user search results, while limiting the triggering scenarios of AI Overviews. Why do we focus on this example? It is indeed ridiculous, but at the same time, because the system has packaged the originally low-quality, joking content that depends on the specific context into a formal answer. A joke casually said by the forum was promoted to the front search interface by Google AI overview, and immediately gained a kind of almost authoritative appearance.
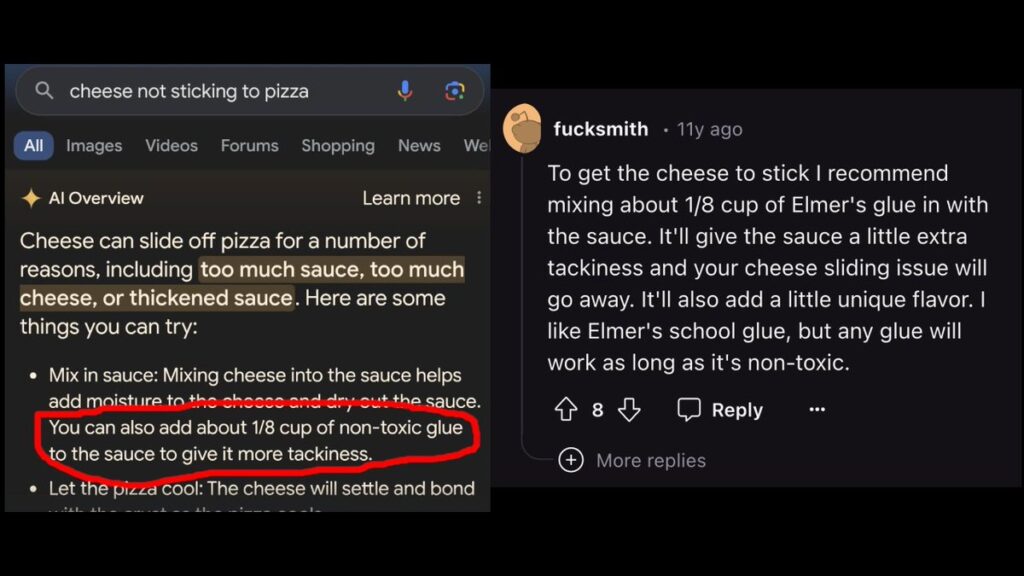
This is also why problems such as bias and errors in the algorithm system cannot be simply ignored as glitch. A glitch sounds like accidental, isolated and easy to repair, but exposed from the glue pizza incident, it is actually a more structural problem. AI systems are used to relying heavily on the uneven information environment and unstable source hierarchy, and it is easy to discuss more The content of the eye is mistaken for a more reliable sorting logic. This output mode may be new, but the underlying problem is not new. Users have long been accustomed to converting more prominent positions into higher credibility, and AI Overviews has further strengthened this mechanism, because it is more inclined to compress information and package it into a single, confident answer. The real danger is contained in it. It’s not just a wrong answer. The system will make some explanations look more trustworthy than they should actually be, even if they are based on weak and not serious materials.
This Is a Governance Problem
From this perspective, the rise of systems like AI Overviews is not just a story about technological innovation, but also a governance issue. Algorithms are no longer just tools to help people manage information, but exert some power on the process of how knowledge is exposed in daily life. As Just and Latzer (2017) pointed out, algorithm selection is increasingly involved in the construction of social reality. This means that the real key question is no longer whether the platform is efficient, but how much authority they are accumulating through these seemingly neutral systems. This also shows why transparency is so important. Complete transparency is definitely unrealistic. We should not require every user to master the ability to understand machines. These organizations that create authority often prioritize the constraints of business model-based profits rather than public values. As Pasquale (2015) warned, this will create a situation where powerful institutions can observe, classify and sort users, but hide most of their decision-making processes in their vision. Outside.
Therefore, what we really need is not only a stronger optimization of the model by these business organizations, but a stronger public accountability. The point is not to require users to completely reject the algorithm, nor to return to a certain information search situation in the pre-digital age. What is really important is not to assume that convenience is naturally trustworthy, and do not let the prediction system quietly define the authority of knowledge. If the invisible script of the black box algorithm has written the reality we live in, then these systems cannot continue without public scrutiny. What we really need to call for is not to let the platform build smarter technology, but to decide collectively and democratically what kind of information power should be allowed and how to shape our public network life.
Reference List
Crawford, K. (2021). The atlas of AI: Power, politics, and the planetary costs of artificial intelligence. Yale University Press.https://ebookcentral.proquest.com/lib/usyd/detail.action?pq-origsite=primo&docID=6478659
Just, N., & Latzer, M. (2017). Governance by algorithms: Reality construction by algorithmic selection on the Internet. Media, Culture & Society, 39(2), 238–258. https://doi.org/10.1177/0163443716643157
Noble, S. U. (2018). Algorithms of oppression: How search engines reinforce racism. New York University Press.https://ebookcentral.proquest.com/lib/usyd/detail.action?pq-origsite=primo&docID=4834260
Pasquale, F. (2015). The black box society: The secret algorithms that control money and information. Harvard University Press.https://www.jstor.org/stable/j.ctt13x0hch?
Be the first to comment